Keywords AI
Introduction: A Common Developer Problem
Source: https://arxiv.org/pdf/2505.06120
If you’ve built an AI agent, you’ve probably run into this: the agent starts strong, but as the conversation goes on, it gets confused, forgets earlier context, or misinterprets new input. This isn’t just a bug—it’s a core limitation in how today’s LLMs handle multi-turn conversations.
Recent research from Microsoft and Salesforce shows just how serious the problem is: even the best LLMs see performance drop by 39% when a task is spread across multiple turns instead of a single prompt. And this isn’t just an open-source issue — it affects every model, no matter how big or powerful. The root cause isn’t a lack of intelligence, but how LLMs process information step by step.
In this blog, we’ll break down why multi-turn performance falls apart, based on the paper “LLMs Get Lost in Multi-Turn Conversation.” More importantly, we’ll walk through practical fixes—including a simple trick that boosts accuracy by 80%, and a proven system design that makes your AI apps far more reliable.
Understanding Single-Turn and Multi-Turn Conversations
To grasp the root of the problem, it is essential to distinguish between the two primary ways we interact with LLMs. The distinction between these paradigms explains the gap between how models are benchmarked and how they are used in real-world applications.
What is a Single-Turn conversation?
A single-turn conversation is a "fully-specified" interaction where the user provides all the necessary information, context, and constraints in one complete prompt. The task is entirely defined from the outset, leaving no room for ambiguity.
Example: "Write a Python function that takes a list of integers, nums, and returns the sum. The function signature is def sum_list(nums):."
This "lab-like" setting is the standard for most traditional LLM evaluation benchmarks. While useful for measuring a model's raw capabilities, it does not reflect the dynamic nature of most human-AI interactions.
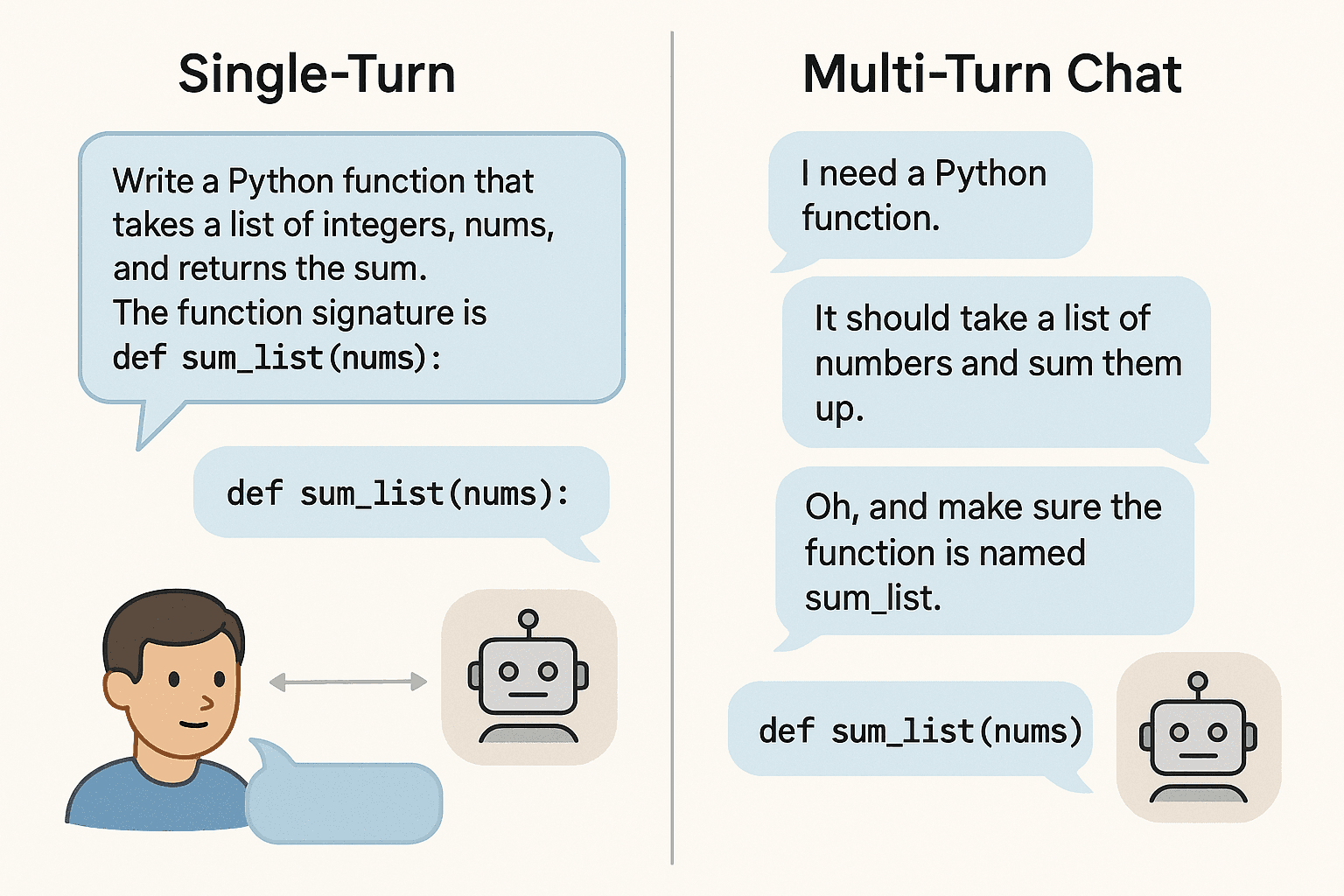
What is a Multi-Turn conversation?
A multi-turn conversation is a dialogue that unfolds more naturally, where information is initially "underspecified" and is clarified or expanded upon piece-by-piece over several exchanges.
A user might begin with a high-level goal and progressively add details or correct the model's understanding. This conversational approach is necessary for exploring complex problems, asking clarifying questions, and building interactive AI agents that can collaborate with a user.
Example:
- User Turn 1: "I need a Python function."
- User Turn 2: "It should take a list of numbers and sum them up."
- User Turn 3: "Oh, and make sure the function is named sum_list."
The Problem: "Lost in Conversation"
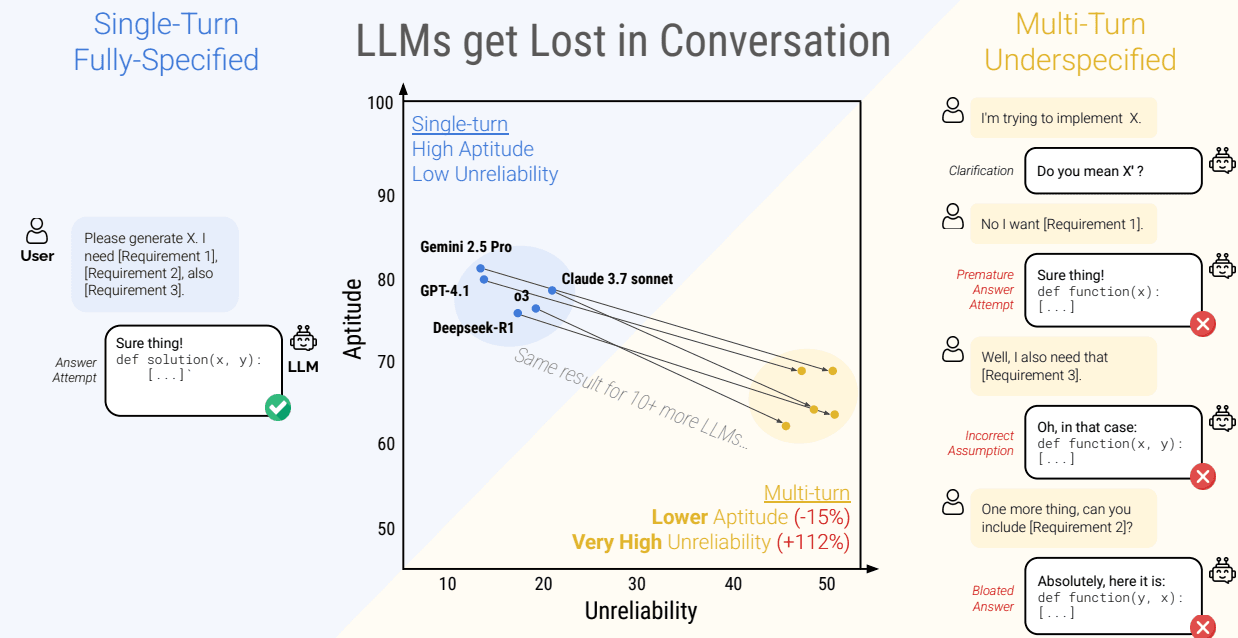
In the paper “LLMs Get Lost in Multi-Turn Conversation,” Microsoft and Salesforce researchers pinpoint why models that perform well in single-turn tasks often fail in multi-turn chats.
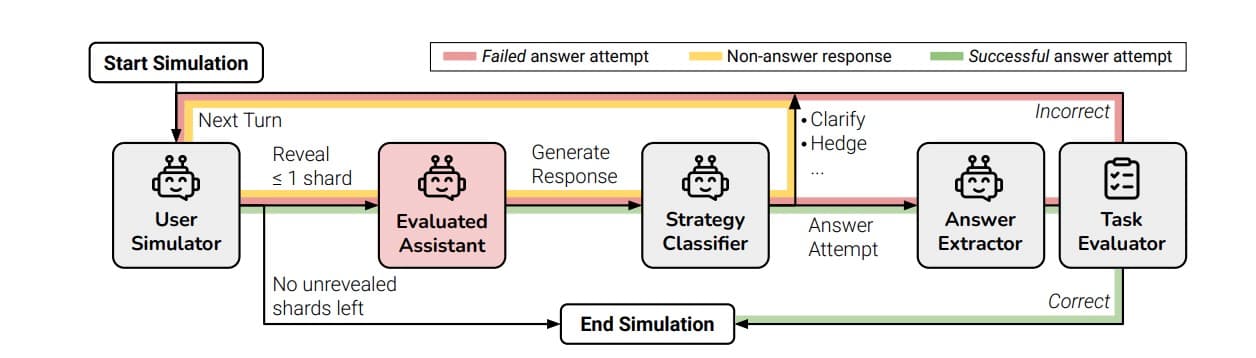
The Experiment: "Sharding"
To test this, the team used a method called sharding. They took a fully-specified prompt and split it into smaller pieces—called shards—each containing part of the original instruction. These shards were then fed to the model one at a time, simulating a real conversation where users share information gradually.
This setup let them compare model performance on the exact same task—once in a single prompt, and once over multiple turns.
The Core Issue: Reliability, Not Aptitude
The model’s aptitude—its best-case ability to solve the task—dropped by just 16% in multi-turn mode. But the real issue was reliability. The consistency of its output tanked, with unreliability (measured as the gap between best- and worst-case performance) increasing by 112%.
So while the model still can do the task, it becomes far less predictable as the conversation unfolds.
A Predictable Failure Pattern
This breakdown happens in a consistent, three-step pattern:
-
Premature Assumptions Early on, with limited context, the model fills in missing details on its own—often incorrectly.
-
Anchoring on Errors Once it makes these assumptions, it sticks to them. The model begins treating its own earlier outputs as truth, sometimes overvaluing them compared to new user input.
-
Failure to Course-Correct When corrected, it struggles to revise its thinking. Instead of starting fresh, it awkwardly tries to bolt new facts onto a flawed base—resulting in bloated, confusing, or completely wrong outputs.
Even when it eventually lands on the right answer, the response tends to be longer, messier, and less clear than if it had just received everything upfront.
LLM Performance: Single-Turn vs Multi-Turn
| Model | Single-Turn Accuracy (FULL) | Multi-Turn Accuracy (SHARDED) | Performance Drop |
|---|---|---|---|
| GPT-4.1 | 96.6% | 72.6% | -25% |
| Gemini 2.5 Pro | 97.4% | 68.1% | -30% |
| Claude 3.7 Sonnet | 78.0% | 65.6% | -16% |
| Llama3.1-8B | 27.4% | 15.7% | -43% |
| Average Across All Models | ~90% (for top models) | ~55% (for top models) | -39% |
The Fix: "Concat-and-Retry"
The researchers found a surprisingly simple fix: don’t let the model carry the baggage of the entire conversation into the final task. Instead, start fresh—once all the info is gathered, re-prompt the model cleanly.
Source: Simple fix for LLMs getting lost in multi-turn conversations
How It Works
-
Gather: Use the multi-turn chat to ask questions, clarify details, and collect requirements. Store these in a structured format (like a list or dictionary).
-
Consolidate: Once everything’s confirmed, generate a single, clean prompt that includes all the finalized information.
-
Retry: Send this new prompt to a fresh LLM instance—with no memory of the prior conversation. This reset is crucial.
The Impact
This “concat-and-retry” method works shockingly well. In the paper, using this approach pushed model accuracy back above 90% for top models—nearly matching single-turn performance. Even RECAP, a variation that adds a summary before retrying, saw major gains over standard multi-turn chats.
Developer Example (Pseudo-code):
python1# 1. GATHER INFO in a multi-turn chat 2# This loop represents your chatbot's conversation with the user. 3user_requirements = 4while not conversation_is_complete(): 5 user_input = get_user_input() 6 #... logic to process input, ask clarifying questions... 7 # and extract a confirmed requirement. 8 confirmed_requirement = extract_requirement(user_input) 9 if confirmed_requirement: 10 user_requirements.append(confirmed_requirement) 11 12# 2. CONSOLIDATE 13# Build a single, clean prompt from all gathered requirements. 14final_prompt = "Please perform the following task with all these requirements: \n" 15for req in user_requirements: 16 final_prompt += f"- {req}\n" 17 18# 3. RETRY: Send to a new, stateless LLM instance for a clean execution. 19# This should be a separate API call with no prior message history. 20final_result = llm.generate(prompt=final_prompt, history=) 21 22print(final_result)
Making Multiple LLMs Work Together
The "concat-and-retry" method isn’t just a clever trick—it’s the foundation for a more reliable system. By turning it into a formal design pattern, you can build AI apps that are naturally resilient to the "lost in conversation" problem.
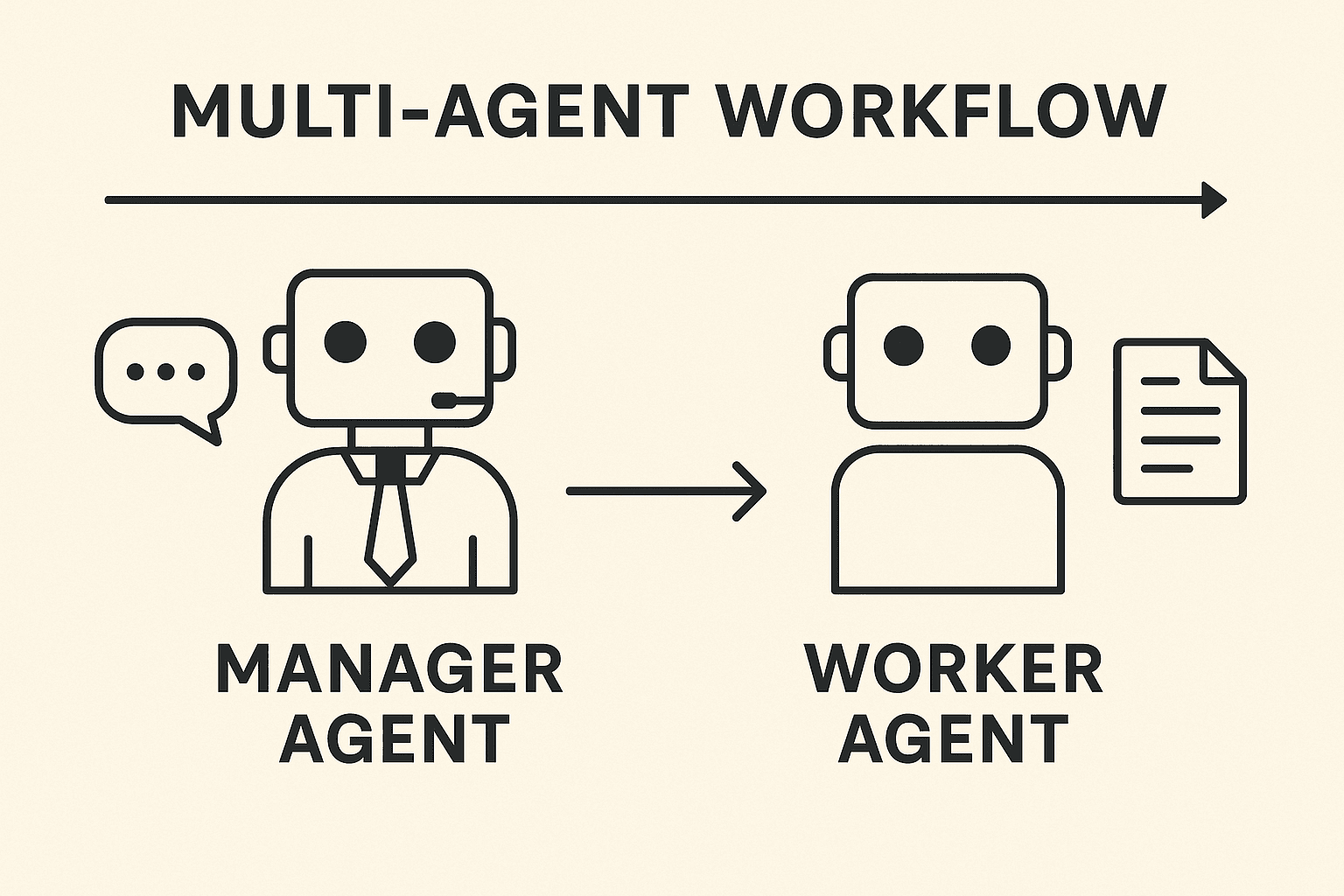
The Manager–Worker Model
This pattern separates the conversation from the task execution using two specialized agents:
-
Manager Agent Handles the conversation. Its job is to ask smart questions, collect user requirements, and build a clear spec. It doesn’t do the core task—it just gathers and organizes information.
-
Worker Agent Executes the task. Once the spec is ready and confirmed, the Manager passes a clean, consolidated prompt to the Worker. The Worker has no memory of the messy conversation—it just sees the final instruction and executes it accurately.
This setup creates "computational hygiene": the Manager deals with the messy, back-and-forth chat; the Worker gets only the clean, finalized input. It’s a clean handoff from noisy context to focused execution.
Why This Works
-
Reliable by Design This model directly applies the concat-and-retry fix. It makes unpredictability in multi-turn chats a non-issue.
-
Efficient and Cost-Effective You can use a lightweight, cheaper model (like Claude 3 Haiku) for the Manager, and reserve a high-performance model (like GPT-4.1) for the Worker. That keeps quality high and costs low.
-
Aligned with Modern Frameworks This architecture matches the direction of agentic frameworks like AutoGen and LangChain, which use specialized agents to handle different tasks in complex workflows.
Conclusion
The "lost in conversation" problem is a core limitation in how today's LLMs handle multi-turn conversations. By understanding the problem and applying the "concat-and-retry" method, you can build AI apps that are naturally resilient to this issue.
By using the Manager–Worker model, you can build AI apps that are more reliable and efficient.
Key Takeaways
This research offers practical lessons for anyone building conversational AI:
-
The problem isn’t intelligence—it’s reliability. LLMs struggle in multi-turn conversations because they get anchored to early assumptions and fail to adapt when new information is introduced.
-
The best fix: start fresh. The "Concat-and-Retry" method—gathering all requirements first, then sending a clean, consolidated prompt to a fresh LLM—restores performance.
-
Turn the fix into architecture. Implement this pattern using a Manager–Worker model: the Manager handles the conversation, the Worker executes the task with a clean slate. This simple design shift can significantly boost your AI app’s reliability and output quality.


