Keywords AI
Building reliable LLM applications requires more than just writing workable prompts. It demands a systematic approach to design, evaluation, iteration, and production monitoring. As language models become increasingly integrated into business-critical applications, developers need robust workflows that ensure consistent performance and continuous improvement.
This guide walks through the complete prompt engineering lifecycle, from initial development to production optimization, using practical examples and proven methodologies that leading AI teams use in 2025.

Why Systematic Prompt Engineering Matters in Production
Unlike traditional software where bugs are obvious, LLM outputs can be subtly wrong, inconsistent, or fail edge cases that only emerge at scale. This makes evaluation critical for production reliability.
We used to label data to train models. Now we also need to label model outputs to ensure they meet our standards—completing the AI development circle.
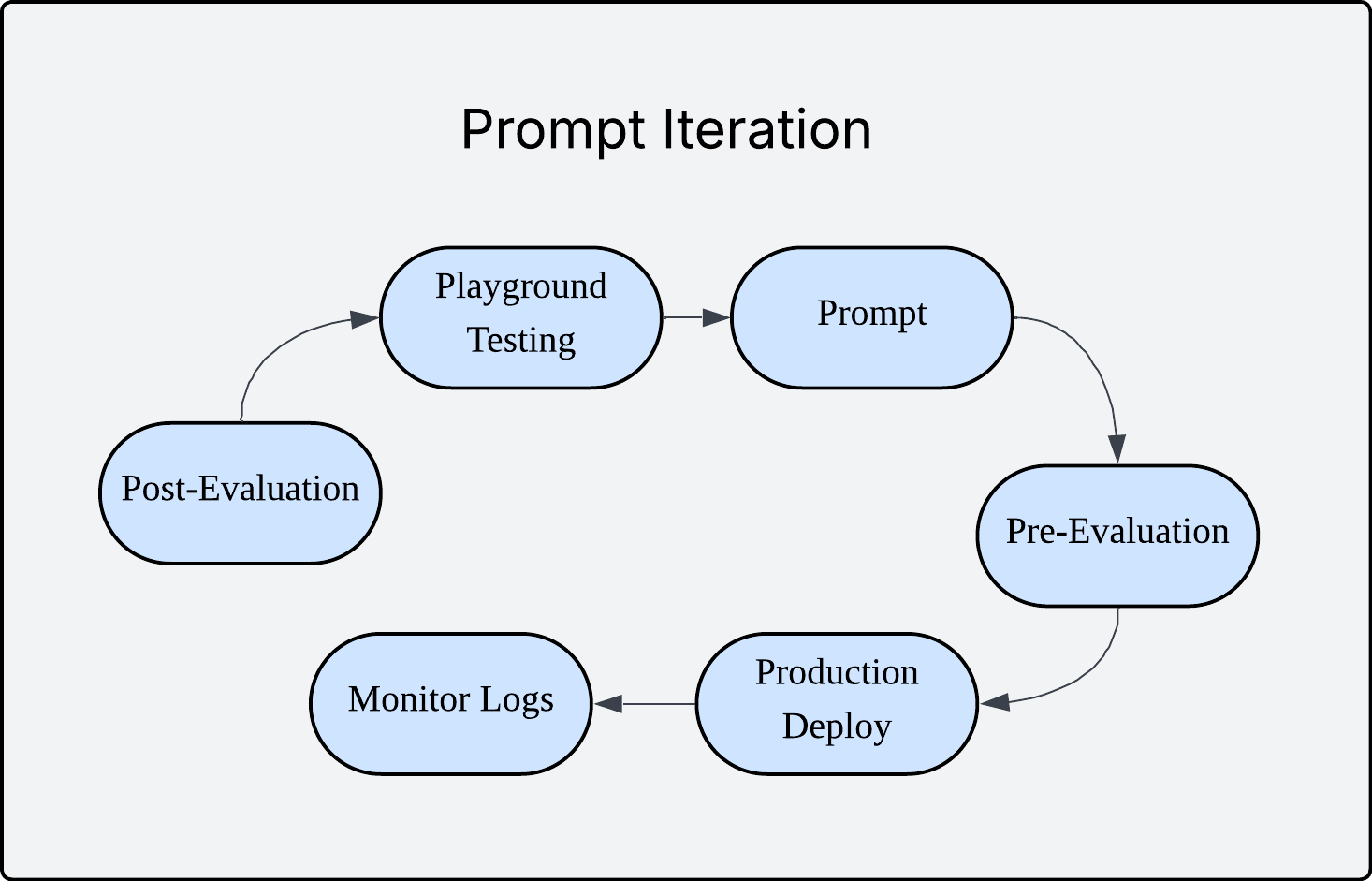
Step 1: Crafting Your Initial Prompt Structure
The foundation starts with well-structured prompts. Your system prompt defines the AI's role and behavior, while user prompts handle dynamic inputs through variables.
System Prompt Example
You are an expert customer service representative for a SaaS company.
You respond professionally, empathetically, and provide actionable solutions.
Always maintain a helpful tone and ask clarifying questions when needed.
User Prompt with Variables
Customer Issue: {{ customer_issue }}
Customer Tier: {{ tier_level }}
Previous Interactions: {{ interaction_history }}
Please provide a personalized response addressing their concern.
There's a lot of so-called "prompt frameworks" in the world, but the key is creating prompts that are flexible enough to handle various inputs while being specific enough to produce consistent results. Create prompts via Keywords AI
Step 2: Implementing JSON Schema for Structured Responses
Structured outputs are crucial for production applications. JSON schemas ensure your LLM responses integrate seamlessly with your application logic.
json1{ 2 "name": "meeting_time_suggestion", 3 "schema": { 4 "type": "object", 5 "properties": { 6 "suggestedTime": { 7 "type": "string", 8 "description": "Meeting time in HH:MM format (24-hour).", 9 "pattern": "^([01]\\d|2[0-3]):[0-5]\\d$" 10 }, 11 "duration": { 12 "type": "string", 13 "description": "Meeting duration in minutes, represented as an integer string.", 14 "pattern": "^\\d+$" 15 }, 16 "title": { 17 "type": "string", 18 "description": "The meeting title, extracted or improved from user request.", 19 "minLength": 1 20 }, 21 "description": { 22 "type": "string", 23 "description": "A brief description of the meeting based on user request.", 24 "minLength": 1 25 }, 26 "reasoning": { 27 "type": "string", 28 "description": "Rationale for choosing this time; must mention conflicts avoided.", 29 "minLength": 1 30 } 31 }, 32 "required": [ 33 "suggestedTime", 34 "duration", 35 "title", 36 "description", 37 "reasoning" 38 ], 39 "additionalProperties": false 40 }, 41 "strict": true 42}
This approach ensures your application receives predictable, parseable responses that can trigger appropriate workflows, escalations, or analytics.
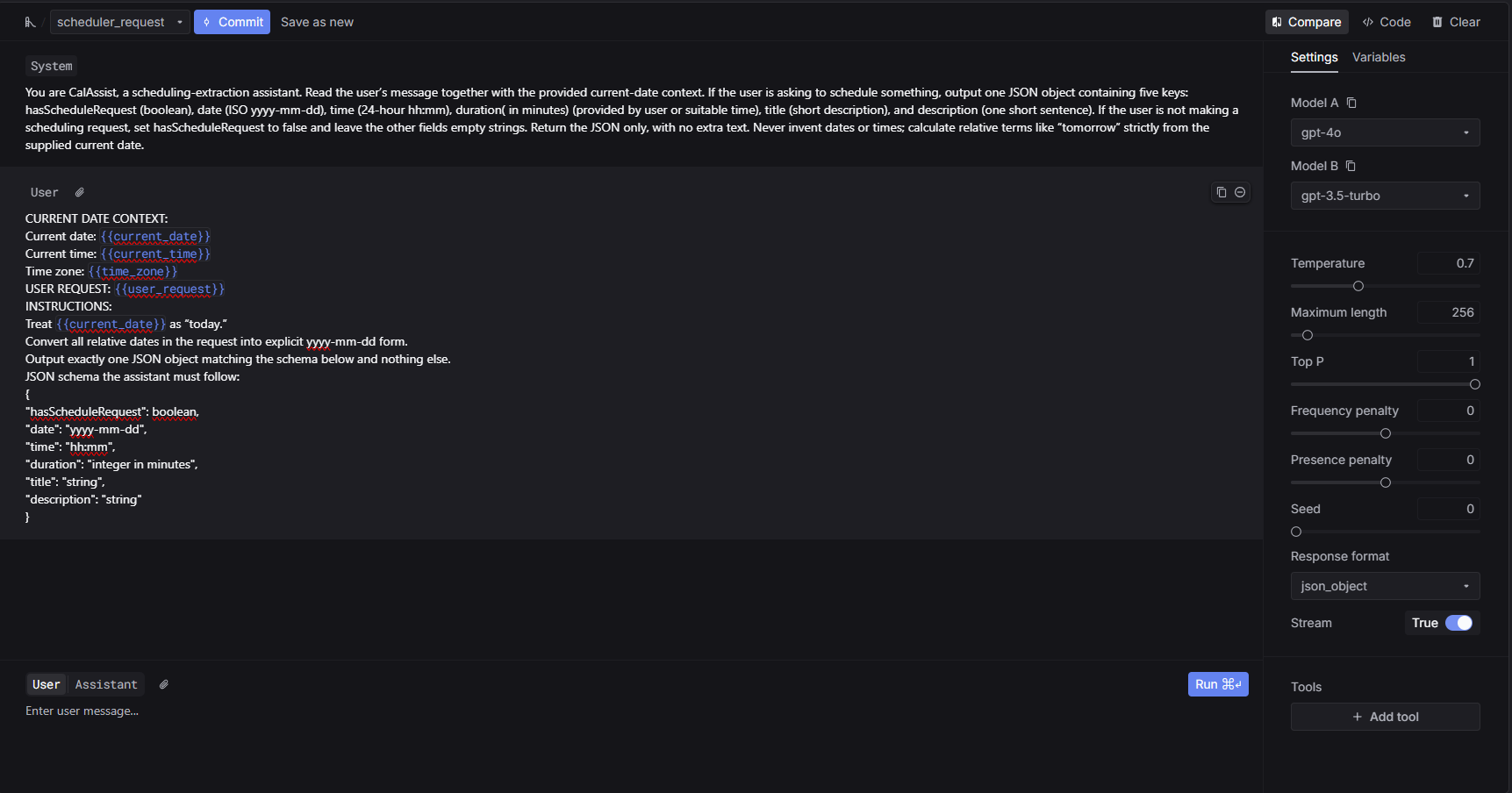
Step 3: Testing in the playground environment
Once you've crafted your initial prompt and response schema, the playground becomes your testing ground. This is where you validate your approach with various inputs and edge cases.
Start with happy path scenarios using typical, expected inputs. Then test edge cases with unusual or boundary inputs. Try error scenarios to see how the prompt handles invalid requests. Finally, run variation testing to ensure consistent responses to similar inputs.
During playground testing, pay attention to response consistency across similar inputs, adherence to your JSON schema, appropriate handling of edge cases, and overall response quality and relevance.
The playground environment allows rapid iteration without the overhead of production deployments, making it the ideal space for prompt refinement. Keywords AI Playground
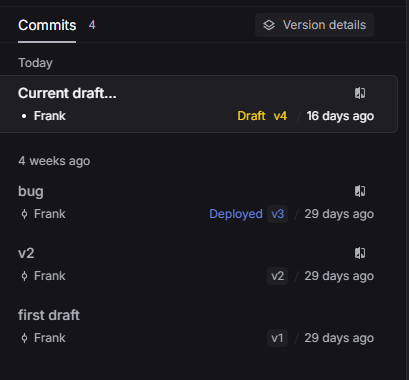
Step 4: Version control and prompt management
Treating prompts like code is essential for maintaining reliable LLM applications. Version control enables you to track changes, roll back problematic updates, and manage different environments.
Use semantic versioning like v1, v2 with clear commit messages describing changes. Deploy to different environments (dev, staging, production) and maintain rollback capabilities for quick issue resolution.
When you save your first prompt, you're creating v1. Each iteration becomes a new version that you can deploy, test, and potentially roll back. This approach provides the reliability and traceability that production applications demand.
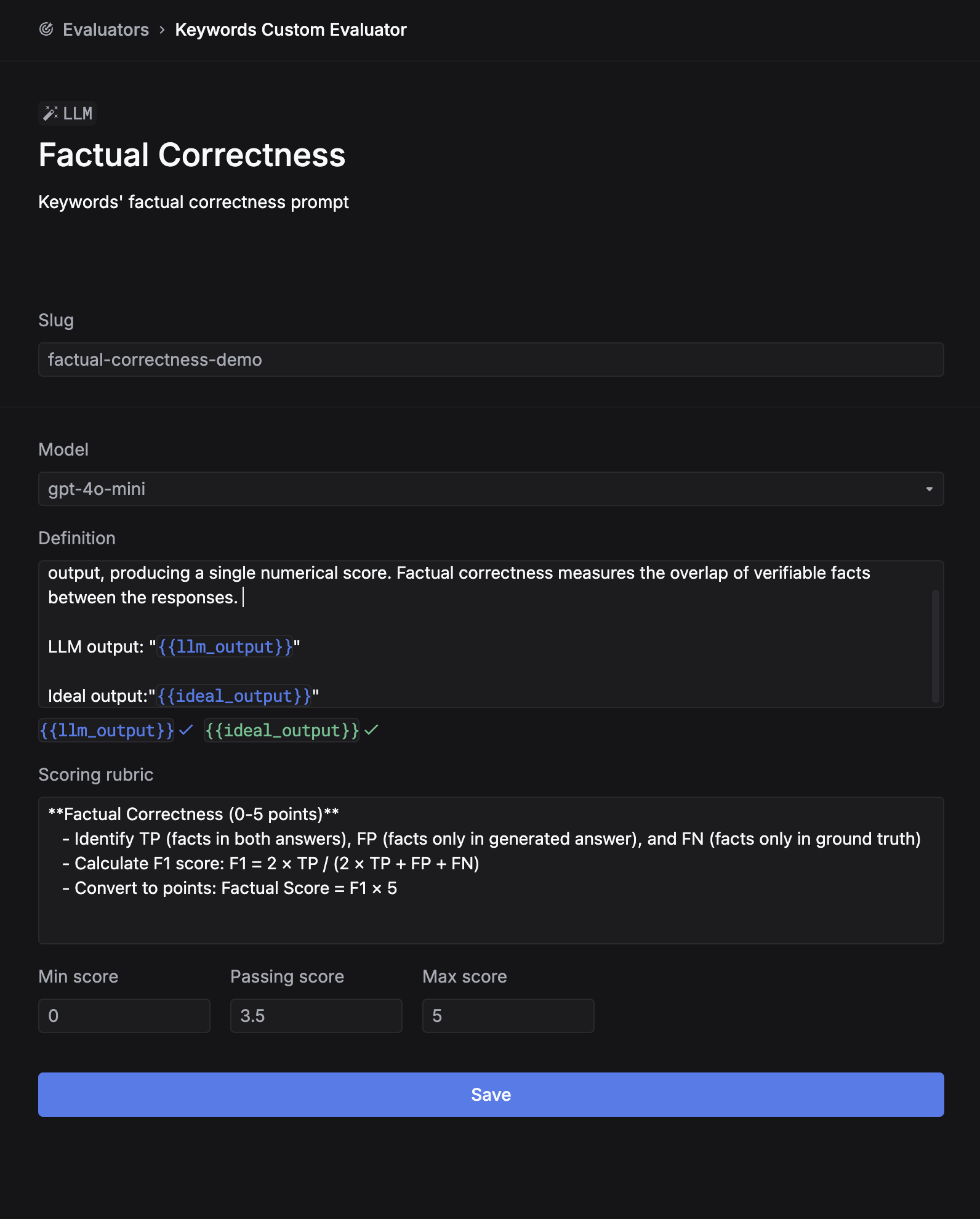
Step 5: Setting up evaluators
Implementing LLM-based evaluators
Automated evaluation using LLMs provides scalable quality assessment. These evaluators can score outputs across multiple dimensions like accuracy, helpfulness, and professionalism.
Adding human evaluation
While LLM evaluators provide speed and consistency, human evaluation ensures quality aligns with actual user needs. Human evaluators excel at nuanced quality assessment, cultural appropriateness, edge case identification, and bias detection.
The most effective evaluation systems combine both automated and human assessment, leveraging the strengths of each approach. Keywords AI evaluators
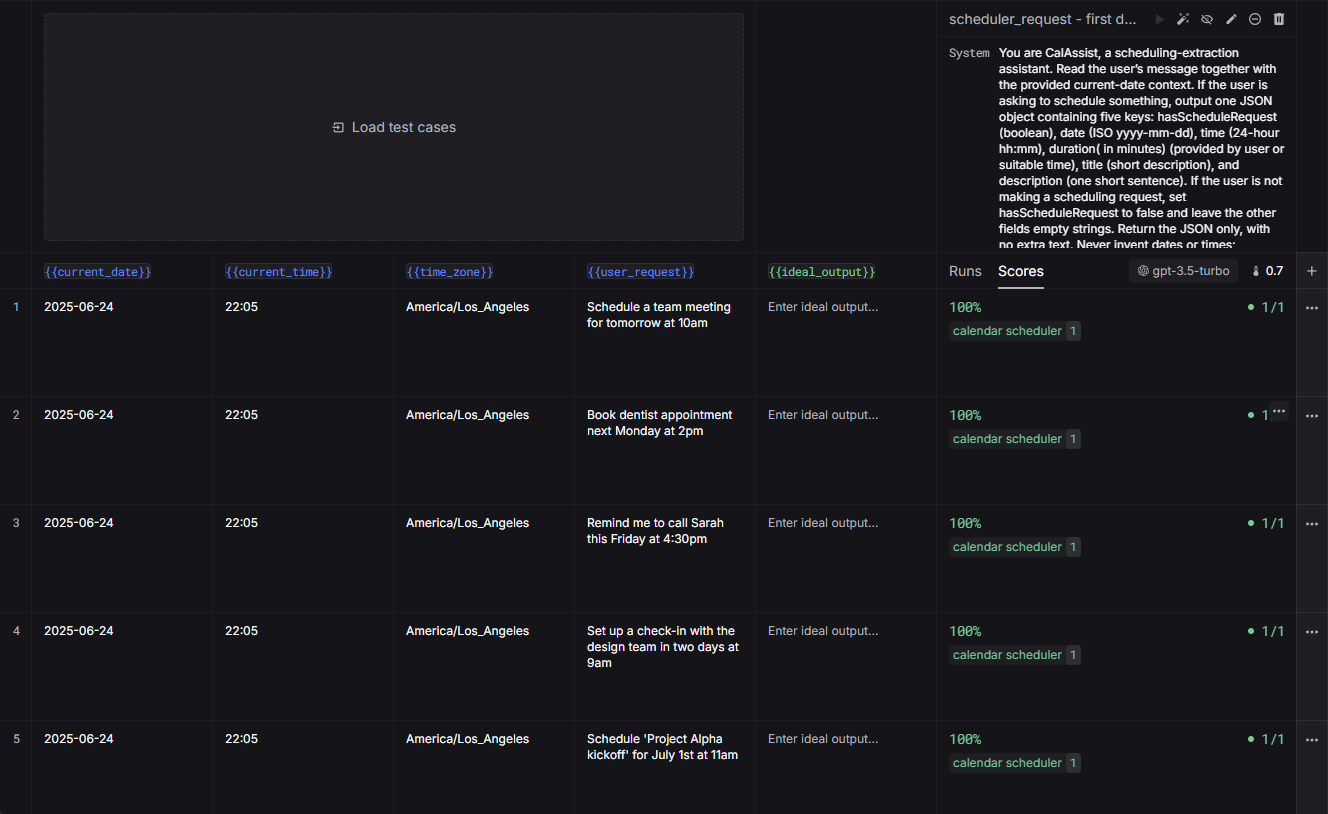
Step 6: Pre-production experiments with curated test sets
Before deploying to production, create test sets that represent your expected use cases. These should include diverse input scenarios, known correct outputs, edge cases and potential failure modes, and representative user interactions from your domain.
With your test set ready, run comprehensive evaluations to establish performance baselines:
Step 7: Post-production monitoring and feedback loops
Once you push your prompt to production, it's crucial to set up ongoing monitoring and feedback loops to ensure continued performance and user satisfaction. With Keywords AI, you can setup an offline evalutation running evaluation on your production data. You can also setup an online evaluation running evaluation on your production traffic.


