Keywords AI
Anthropic's latest release, Claude 3.5 Haiku, promises to combine speed with enhanced capabilities. While maintaining similar speed to its predecessor, it shows significant improvements across various benchmarks, even outperforming the previous flagship model, Claude 3 Opus, in several areas.
This comparison between Claude 3.5 Haiku and Claude 3.5 Sonnet aims to help you make an informed choice: whether to prioritize speed and cost efficiency with Haiku, or opt for Sonnet's superior performance capabilities.
Comparison methodology
Our analysis utilizes Keywords AI's LLM playground, a platform that supports over 200 language models and offers function-calling capabilities. We'll explore the following aspects:
- Basic comparison
- Benchmark comparison
- Processing speed
- Evaluation metrics
- Suggested use cases
Basic comparison
| Claude 3.5 Haiku | Claude 3.5 Sonnet | |
|---|---|---|
| Input | $1.00 / 1M tokens | $3.00 / 1M tokens |
| Output | $5.00 / 1M tokens | $15.00 / 1M tokens |
| Context window | 200K | 200K |
| Max output tokens | 8192 | 8192 |
| Supported inputs | Text and Images | Text and Images |
| Function calling | Yes | Yes |
| Knowledge cutoff | July 2024 | April 2024 |
Benchmark comparison
| Benchmark | Claude 3.5 Haiku | Claude 3.5 Sonnet |
|---|---|---|
| MMLU Pro | 65.0 | 78.0 |
| GPQA Diamond | 41.6 | 65.0 |
| MATH | 69.4 | 78.3 |
| HumanEval | 88.1 | 93.7 |
Claude 3.5 Sonnet demonstrates consistently higher performance across all benchmarks. The most notable gap appears in GPQA Diamond, where Sonnet (65.0%) outperforms Haiku (41.6%) by 23.4 percentage points.
Both models show strong capabilities in code generation (HumanEval), though Sonnet maintains its edge with 93.7% versus Haiku's 88.1%. These results indicate that while both models are capable, Sonnet offers superior performance for complex tasks.
Speed comparison
Generation time
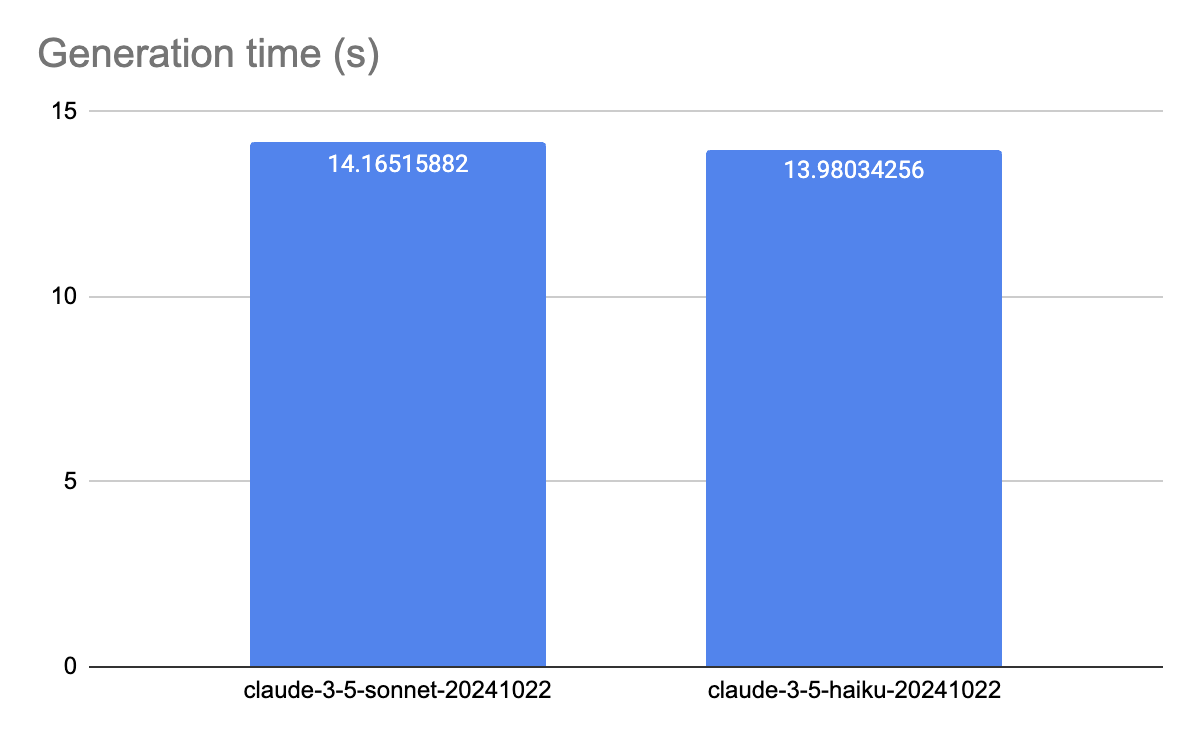
Our extensive testing, conducted across multiple requests, shows minimal difference in latency between the two models. Claude 3.5 Haiku demonstrates slightly faster performance at 13.98s/request, while Claude 3.5 Sonnet follows closely at 14.17s/request.
Speed (Tokens per second)
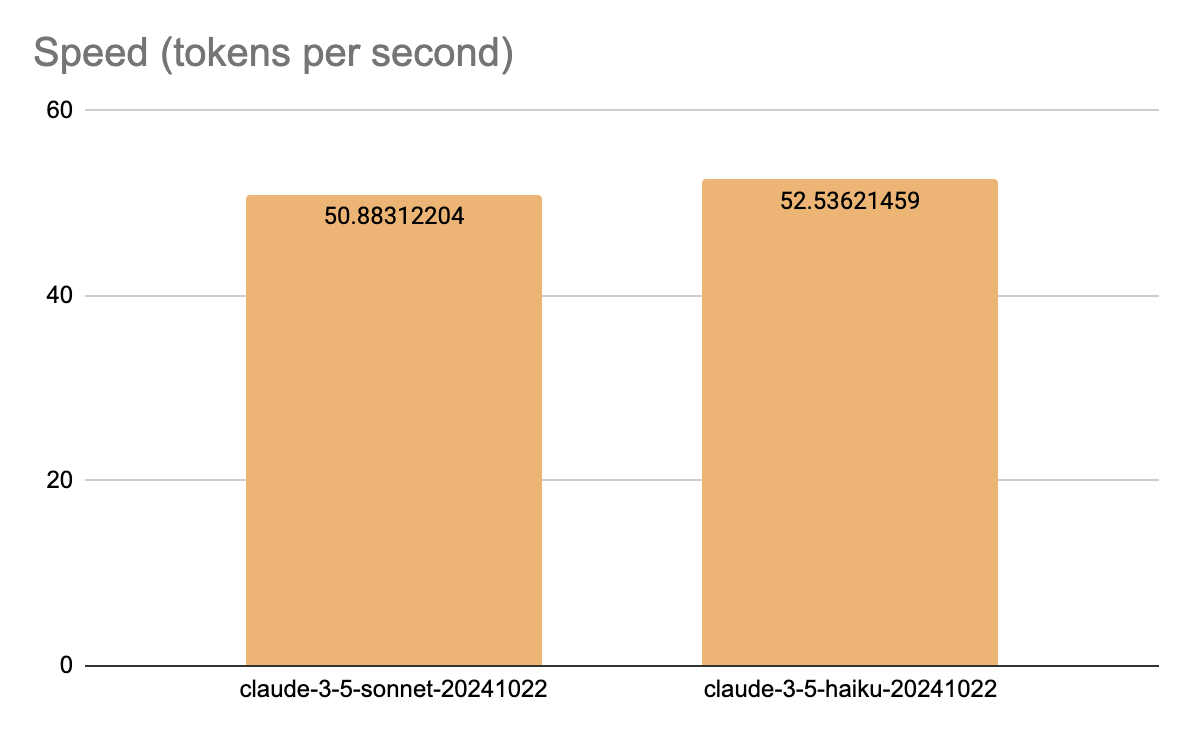
The throughput comparison reveals similar token generation capabilities. Claude 3.5 Haiku leads slightly with 52.54 tokens/second, while Claude 3.5 Sonnet generates 50.88 tokens/second.
TTFT (Time to First Token)
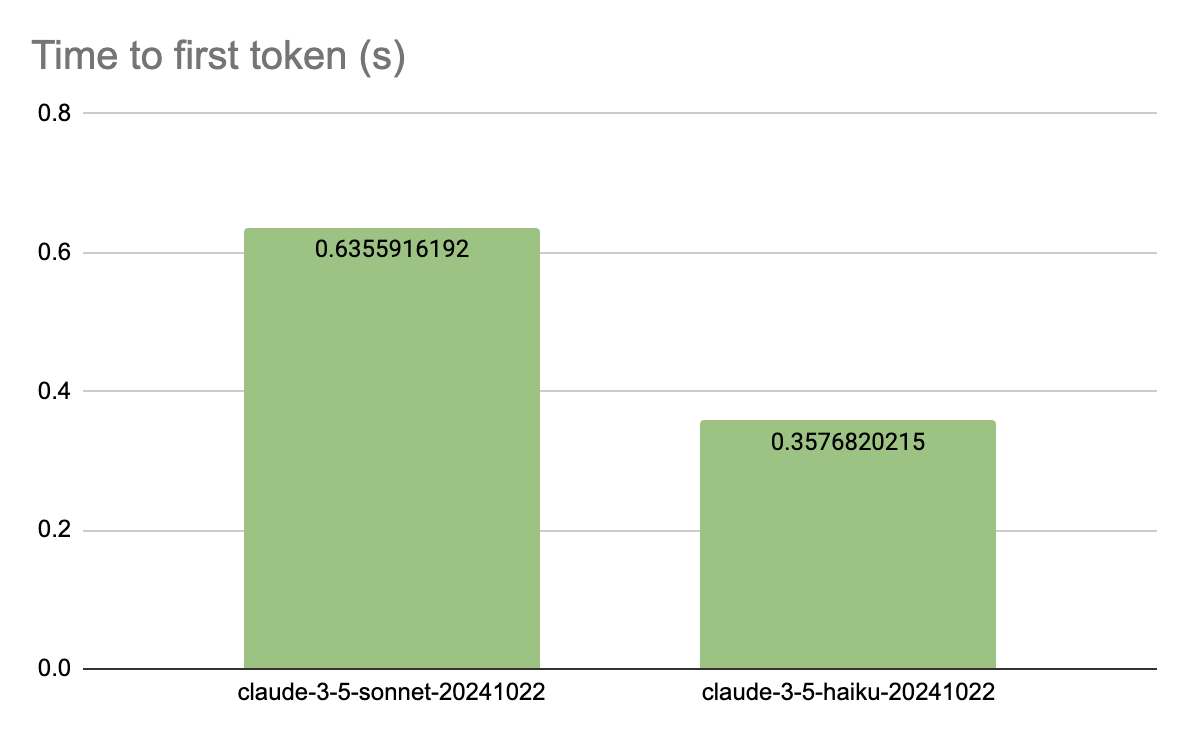
Claude 3.5 Haiku demonstrates significantly faster initial response with a TTFT of 0.36 seconds, while Claude 3.5 Sonnet takes 0.64 seconds.
Overall, Haiku shows slightly better speed performance across all metrics. While the latency difference is minimal (13.98s vs 14.17s), Haiku has a faster first response time (0.36s vs 0.64s) and slightly higher throughput (52.54 vs 50.88 tokens/s). If speed is your primary concern—especially for real-time applications or chat-like interfaces—Haiku is a better choice.
Performance comparison
We conducted evaluation tests on the Keywords AI - an LLM observability and evals platform. The evaluation comprised 5 parts:
- Coding Task: While both models handle basic coding tasks well, Sonnet demonstrates superior capabilities in complex scenarios. Haiku performs adequately for simple frontend/backend tasks but tends to hallucinate when generating code exceeding 150 lines. Sonnet manages difficult problems more effectively and maintains accuracy with longer code blocks.
- Logical Reasoning: Sonnet shows consistently strong performance across various reasoning challenges. Haiku, while capable, occasionally struggles with more complex problems, showing some limitations in advanced reasoning tasks.
- Writing Task: Both models produce quality content, but Sonnet edges ahead with more natural, human-like writing and better prompt comprehension. Its outputs tend to be more nuanced and contextually appropriate.
- Hallucination: Both models generally maintain factual accuracy. However, Haiku shows a higher tendency to hallucinate when dealing with tricky questions or longer inputs/outputs. Sonnet demonstrates more reliable consistency across various scenarios.
- Answer Relevancy: While both models typically provide context-appropriate responses, Haiku occasionally produces more verbose outputs. Sonnet maintains better focus and conciseness while addressing the core requirements.
Model Recommendations
Claude 3.5 Sonnet
- Best for: Complex reasoning tasks, professional coding projects, and high-quality content creation. Ideal for applications requiring high accuracy and sophisticated problem-solving.
- Not suitable for: Applications with strict speed requirements or projects with tight budget constraints, as it's slightly slower and likely more expensive.
Claude 3.5 Haiku
- Best for: Quick interactions, simple coding tasks, and applications requiring faster response times. Good for chatbots and real-time applications where speed is crucial.
- Not suitable for: Complex programming projects exceeding 150 lines of code, advanced reasoning tasks, or applications where consistent accuracy is critical for longer outputs.


